
IP Geolocation Demystified
BigDataCloud March 18, 2019
What is IP Geolocation?
This is part 1 of a 2-part series on the current stage of IP geolocation services worldwide. If you are interested in how BigDataCloud is revolutionising the industry, head straight to part 2: The Next Generation IP Geolocation Service.
An Internet Protocol address (IP address) is a numerical label assigned to each device connected to a computer network. This numerical label is used to identify these devices, allowing for direct communication.
The public internet operates with the same principles. When a device connects to the internet it utilises a globally unique IP address to ensure both inbound and outbound communication is delivered correctly.
In this context, the IP address acts in a similar way to a postal address used to deliver conventional mail. However, unlike the postal address, an IP address does not have an intrinsic location and does not expose any geographical properties. This is why you cannot determine the location of a device by its IP address alone.
IP Geolocation is an essential technology that overcomes this limitation to help organisations identify the location of their customers based on their IP addresses. Organisations such as online service operators, financial institutions, search engines, ad agencies and any business offering an online shopping / e-commerce experience are able to provide their customers with the best products and services available in their region. This IP Geolocation service is also crucial for preventing online fraud, managing digital rights, and serving targeted marketing material and pricing.
If you wonder where your online customers are coming from or wish to customise your clients’ online experience based on their location, you are likely familiar with various commercial IP Geolocation services, ranging from free to highly-priced to enterprise-only. Most of these providers declare superior accuracy, although show little transparency on the methodology, and present scarce evidence to support their claimed accuracy.
In general, validation of the accuracy of an IP Geolocation service is challenging and requires a large pool of ground-truth data (i.e. vast numbers of IP addresses from known locations). This data is generally collected from all active ISPs/AS’ and is required to be random, spread over various geographical regions. In reality, such data is generally not available, in which case any claimed IP Geolocation accuracy without full transparency is questionable.
What is the Ultimate Data Source?
The IPv4 protocol uses 32-bit addresses which makes the maximum theoretical address space limited to 4,294,967,296 (232) IP addresses. IPv6, the next-generation protocol, utilises 128-bit addresses which makes the pool considerably larger, but still limited. Due to the global uniqueness requirement of IP Addresses across both protocols, the global IP address space allocation is heavily regulated.
IANA – ‘The internet Assigned Numbers Authority is a function of ICANN, a nonprofit private American corporation that oversees global IP address allocation, autonomous system number allocation, root zone management in the Domain Name System, media types, and other internet Protocol-related symbols and internet numbers.’ (source: Wikipedia).
IANA is responsible for the allocation of large IP address space blocks to the Regional internet Registries (RIRs):
- AFRINIC for Africa Region
- APNIC for Asia/Pacific Region
- ARIN for Canada, USA, and some Caribbean Islands
- LACNIC for Latin America and some Caribbean Islands
- RIPE NCC for Europe, the Middle East, and Central Asia
RIRs in turn delegate a portion of their allocated address space to Local internet Registries (LIRs), e.g. APNIC delegates to the Japan Network Information Center (JPNIC). All registries both regional and local allocate their remaining available address space to organisations seeking to utilise it on the public internet.
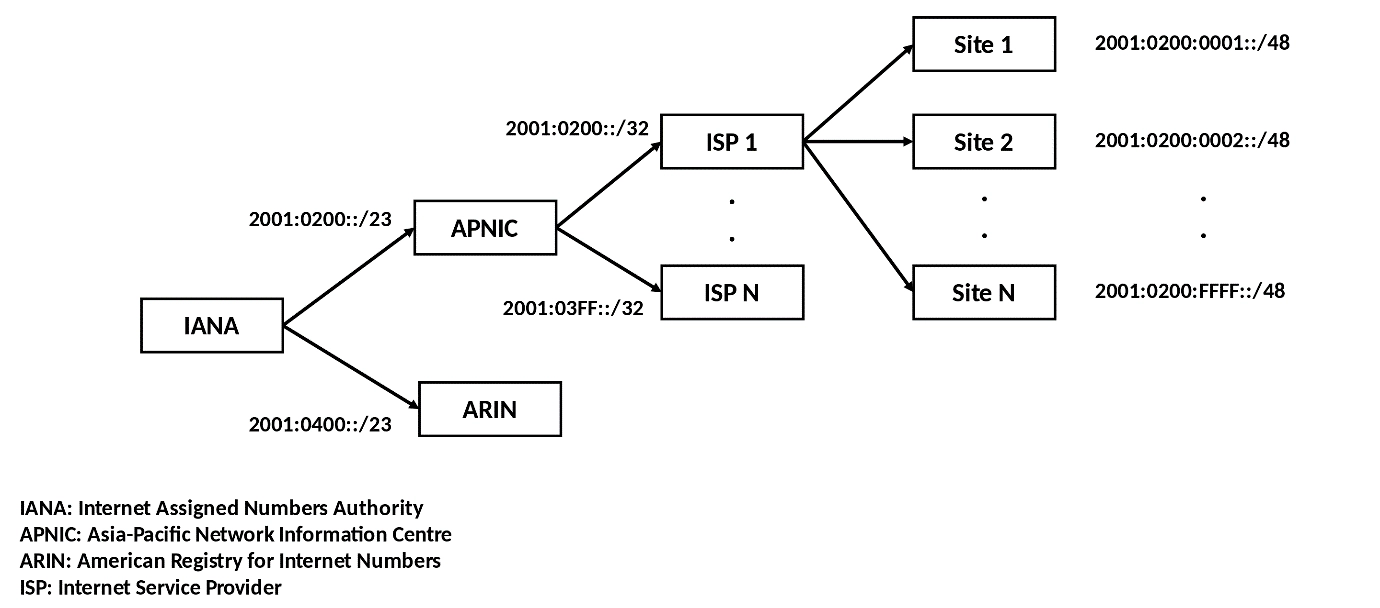
Business entities (or autonomous networks) that are assigned IP address space for their own use are called Autonomous Systems (AS). They must first register as an AS, receiving a globally unique Autonomous System Number (ASN) which can then be used to identify them.
The internet Service Provider (ISP) is the most typical example of an AS operator, but it is not the only one. Virtually, any organisation seeking to use their own IP addresses on the internet qualifies as an AS. It is a common occurrence that AS entities liberally uses their allocated IP space in any manner they wish, and more importantly, in any geographical location they like. They can allocate it to any AS entity/network within the same enterprise regardless of global location or even sublease it to a completely unrelated, geographically remote entity. Despite existing regulations, there is no way to restrict allocated IP address space geographically.
Therefore, the only ultimately accurate IP Geolocation data is that which is made available by AS operators, who are the only ones who confidently know how and where their IP addresses are utilised. AS, however, are not obliged to share their internal data with any other entity, except for law enforcement agencies within the determined jurisdiction boundaries.
Existing commercial IP Geolocation service providers do not have access to AS internal data. Some of these service providers claim they have integrated services with ISPs or receive data directly from ISPs. Considering there are more than 80,000 registered ASs, of which more than 60,000 are active at any one time (active ASNs ranked list), it is largely impractical to form commercial relationships with all. Receiving the data from a small number of local ISPs may improve regional geolocation accuracy to a minor extent but is not sufficient on a global scale.
Where do IP Geolocation service providers get their data?
Assuming that the existing IP Geolocation services do not have access to the Autonomous Systems’ internal data, they cannot be confident regarding the actual geographical location of the routable IP addresses. So, where are they getting their geolocation data from?
WhoIs Data
WhoIs is by far the most common source of geolocation data. WhoIs database is nourished by Regional and Local internet Registry organisations (RIR/LIR) that are obligated to keep their registration records public. This information discloses all IP addresses registered for each entity they belong to, including independent organisations or ISPs. IP Geolocation service vendors can obtain this registry data using RIR websites and APIs, or can request bulk access to the data. This data is usually updated on a daily basis and include a set of registration data. This registration data contains the IP address block records and which organisations they are registered under. It may additionally contain a street address or the network location coordinates, although none of the geographical properties are mandatory. Furthermore, these records are maintained by the registered party and are not validated by any external body. This means the accuracy of the data is questionable even when it is made available.
There are around 10 million records in the global WhoIs database for IPv4 alone, some of which can serve a very accurate IP Geolocation source. For example, a small internet Cafe with a static IP address (or small range of addresses) used on premises and recorded into the RIR database inclusive of its physical address. This scenario exposes accurate geolocation information with a precision up to a street address. In most cases, when an organisation reports incorrect or outdated information, or outsources the registered address blocks to another party, the records will not reveal the IP usage location.
Therefore, IP Geolocation based on WhoIs database only is largely inaccurate as whole.
BGP Data
The Border Gateway Protocol (BGP) is a global internet address routing directory. This is a standardised exterior gateway protocol to exchange routing information amongst active Autonomous Systems (AS) on the internet. BGP involves the announcement of preferred pathways and direction of internet address blocks (prefixes).
When an AS entity wishes to use an IP address range on the public internet, it has to ‘announce’ it to the closest peers. In simple words, it sends the announcement that means: “I’m responsible for that range (prefix), so whoever wishes to communicate with a device in that range, direct the communication through me”.
This announcement eventually propagates across all other peers worldwide to inform them on how to send a traffic to that IP address range if required. For instance, if I need to send a packet to destination ‘A’, but I only know host ‘C’ and can forward traffic to it. The packet will still reach the desired destination ‘A’, if ‘C’ knows ‘A’ either directly or via other intermediate peers. In a nutshell, this is how global internet connectivity works.
Now, how this can be helpful for IP Geolocation? Firstly, unlike the WhoIs data which shows the organisation registered against a particular IP address block, BGP data can reveal who is actually using it. This is not always the same enterprise entity as we discussed above. If, for example, we witness a block registered with ARIN for an American company with an US street address, but is being used by AS registered with RIPE in Turkey, this suggests that the IP block is likely being used in Turkey, which improves geolocation. Secondly, the BGP data can also reveal what addresses are not used at all, an unannounced space, with which a geolocation process should not even be attempted.
The IP address is not a physical object in a physical location. It is simply a numerical label that can be allocated and unallocated from individual devices or networks. There is no way we can geolocate a label that is not in use (allocated). Therefore, when your IP Geolocation service provider states it can geolocate 100% of the address space, please interpret this with caution as it can only geolocate the announced (routable) space at most. The routable space for IPv4 can be monitored on IPv4 Address Space Report.
Some other usages of BGP data rely on the assumption that IP addresses belonging to certain prefixes are meant to share geographical proximity. This, however, does not always hold true. Prefixes tend to aggregate along the way and may include a cluster of several smaller prefixes that originate from different regions.
Field evidence data
There are many additional data sources that can be utilised for IP geolocation which qualify as field evidence data. The best example is the data received directly from users or submitted using GPS-enabled devices, such as mobile phones or tablets. This data can reveal the alleged geographical coordinates of a device using a public IP address and can serve as empirical evidence or ground-truth data for that particular IP address at that particular moment in time.
Other sources include:
- eCommerce originated data sources/feeds, such as billing/shipping address of the customer when combined with an IP address used for the transaction;
- IoT devices with known locations and IP addresses and device pools, either publicly available or proprietary, for example the RIPE ATLAS project; and
- voluntarily or commercially obtained geolocation data feeds such as Self-published IP Geolocation Data .
There are 2 important principles associated with field evidence IP Geolocation data:
- The data is always limited, as it is impractical for one entity to access all internet-connected devices around the world.
- This method identifies IP location at a specific point in time only and is prone to errors. Not everything can be trusted as pure and reliable evidence. Device misconfiguration or faults and network redirections such as VPN or PROXYs along the way are some of the many data inaccuracy scenarios that can occur during the data collection process.
Scientific data
Over the years, many attempts have been made to introduce an additional active measurement approach to IP Geolocation solutions. Most of these approaches come from the research on time-delay to distance conversions, such as triangulation, down to the closest point of presence (POP) of network interfaces (routers). However, global network traffic interfaces (public routers) are complex, with the assumption that time-delay between two consecutive interfaces is proportional to the physical distance between them is incorrect.
Some large ISPs make their internal subnets hidden. Therefore, many intermediate nodes are not publicly visible and cannot be accounted for. Practical network considerations are based on ‘least cost’ routing, which is different from a common academic assumption of the shortest one. Due to Quality of Service (QoS) considerations, some network interfaces can also be programmed to artificially delay non-productive traffic.
Therefore, the relation between time-delay and distance is inconsistent and cannot lay the foundation for overarching principles. To date, none of the methods based on time-delay triangulation theory have been introduced into the service and are unlikely to emerge for global commercial implementation.
Reverse DNS data
The only known commercially utilised scientific approach has been introduced by Digital Envoy, Inc, protected by US patent (6,757,740) granted in 2004. The method is based on DNS records (textual name of the public internet addresses) and crawling (tracert) to the closest router in an attempt to identify the city and country of the host.
The Domain Name System (DNS) is the phonebook of the internet. Usually DNS is used to translate a domain name to an IP address, so the browsers can load internet resources. However, it can also work in a reverse order, you can query DNS about what domain name record is attached to an IP address. This textual record associated with an IP address is not mandatory. It is hardly of any utility when the address is not involved in publishing internet services or consumable material. However, some ISPs may use this textual tagging opportunity to mark their IP addresses for some internal purposes.
Some of the DNS entries can be potentially used to reveal geographical properties. For example, if the target address or the last router along the way is listed on DNS as an entry: p1-0-0.sanjose1.br2.bbnplanet.net, it suggests that the IP address is likely located in San Jose, California. This method shows an add-on benefit for locating areas with interpretable DNS names.
Unfortunately, the reverse DNS-based approach suffers from several limitations:
- Many interfaces do not have an assigned DNS name;
- The misnaming of an interface results in incorrect location;
- City names can often be repetitive across different countries or territories, i.e. San Jose City can also be found in both Costa Rica and in California, US;
- The lack of universally accepted rules and naming regulations means records require manual processing, which is time consuming and prone to errors.
The art of guessing
The IP Geolocation service providers can obtain their data from multiple sources, although none can serve as an ultimate and undoubtable source of truth. When data is mutually supportive, i.e. multiple sources indicate the very same location for an IP address, it is a no brainer. Often however, the data received is very controversial, and this is where the tricky part lies.
We frequently hear people say that IP Geolocation is part science, part art. Well, here is the art part. The art of guessing! Let’s try to see what your average IP Geolocation service provider is dealing with.
- Imagine we’ve got the field evidence, such as a user-submitted data sample, suggesting that the IP address X.X.X.5 was used today somewhere in Manhattan, in the center of New York City, NY, US.
- The WhoIs data for that address reveals that the block X.X.X.0 - X.X.X.255 (where the above-mentioned address belongs to) is registered for a business ‘Y’ located in Ontario, California, US.
- The BGP data suggests that that address has been announced by an AS entity ‘D’, registered as operated from Austin, Texas, US. And the prefix size was /22 (1024 hosts).
- So, where is the actual location? Can one say that X.X.X.0 - X.X.X.255 block is located in NY?
- Or maybe even entire /22 prefix is in NY too?
- Maybe the X.X.X.5 is the only one in NY and others are not even close?
- Or maybe the sample data we’ve got is wrong and the actual location for all is in Ontario, California or even Texas?
The final conclusion depend on which data source can be trusted the most? Considering there are limited tools to prioritise data sources, the existing IP Geolocation service providers often end up guessing.
Their motto: Any guess is a good guess!
If we happen to obtain more evidence data points from nearby address entries, it would likely improve our confidence, but only if the data support one of the leading guess options.
However, if the data is controversial, it can make geolocation estimation extremely challenging. What if we have further evidence from address X.X.X.128 from Toronto, Canada, dated just a couple of days before? Would this address have moved from Canada to US recently or just a part of the block or are we facing an error somewhere?
This is another complex issue – data granulation. IP addresses are usually deployed in blocks. The larger blocks are better for global routing. If blocks are too small, the world’s routing table substantially expands and the routers can eventually face memory overflow errors. Therefore, IP Geolocation services can logically assume that some consecutive sequences of an IP addresses are likely to share a reasonable geographical proximity. However, defining the actual block IP address boundaries can be tricky and often involves a series of educated guesses which may require intervention from the human operators. For example, one can find similarities in the reverse DNS entries for the block member addresses that possibly suggest the same network. Also, IP addresses can be tracerouted while looking for correlations between the host IP addresses that participate in the packet delivery. Whichever way is chosen, it is commonly prone to errors. DNS entries are not always available or can be wrong. Traceroute does not always reveal all the hosts in the delivery path, as some are simply do not respond to ICMP requests. Perfect host correlation is not always possible, as network routers often use several IP address ports for the same router device. They may appear different on a traceroute but in reality are the same, which may also lead to an error.
So how do IP Geolocation service providers operate?
The entry level IP geolocation providers are likely to use less data sources, largely using WhoIs data only, which limits their decision scope to a much fewer options. This makes the process easier and maybe faster, but as a trade-off, it is much less accurate.
The more advanced IP Geolocation providers presumably work hard to organise and improve their results by delegating many of the final decisions to a human personal, in addition to some low-level automated process. Unfortunately manual work does not guarantee better results, as humans are also prone to errors, and definitely makes the process slower. As a result, we often see commercial IP geolocation databases updated on a monthly basis only, or weekly as the best.
The IP address space is a very dynamic area. Millions of IP addresses changing hands or are reallocated continuously, every hour. Therefore monthly or weekly updates are certainly not suitable for most IP geolocation applications.
In summary, none of the currently existing methods is sufficiently accurate. Even though a combination of methods allows for more precise estimation of IP location, this does not solve the problem of accuracy on a global scale. Moreover, the lack of a fully automated and deterministic methodology prevents existing IP geolocation databases from being updated frequently enough to cope with the highly dynamic nature of the internet IP address space.
To find out how BigDataCloud's IP Geolocation service differs from existing providers, continue reading part 2: The Next Generation IP Geolocation Service.